I recently had the opportunity to work on a mobile project where I faced a whole set of different challenges. All my previous experience involved developing server applications for the web. So when I had to write a REST based API for mobile application we were faced with some interesting challenges.
One of the issues that cropped up is caching of static or rarely changing content. (Not that this is a mobile client issue. But it came up all the same... ) The Mobile app used to show up images of contacts.
These images were served from the server application. Normally when dealing with web applications and static content, you can rely on the browser to do caching even when you haven't done anything on the server to enable it. (Guess browsers are smart or sometimes over smart. Here the server could be chipping in with suitable cache header values ;) )
For stuff like js or images, browsers do a HEAD call to check if anything has changed
If the client was a web-browser, it would cache the static page content.So for subsequent calls, we can depend on browser to do a 304 head call and if on finding that the image has not changed it picks up the content from the local cache. This is pretty well explained here.
But when writing a mobile app all this needs to be done manually. The mobile client must smartly check the headers and decide that the data has not changed and the server call is not needed.
Also with mobiles, space is a big concern. The mobile team we were working with could not decide on caching of images as they had to support a large range of mobiles and big memory availability was not a guarantee. So for now, the decision was that the client app would always hit the server to load the user's picture.
On the server end this scenario seems not too bad as long as the content is static and being served from the web application itself. A straight GET call and the resource is returned by the web server. No work for the application server.
But user's picture was a problem.
We implemented a file system based cache on the server for images.
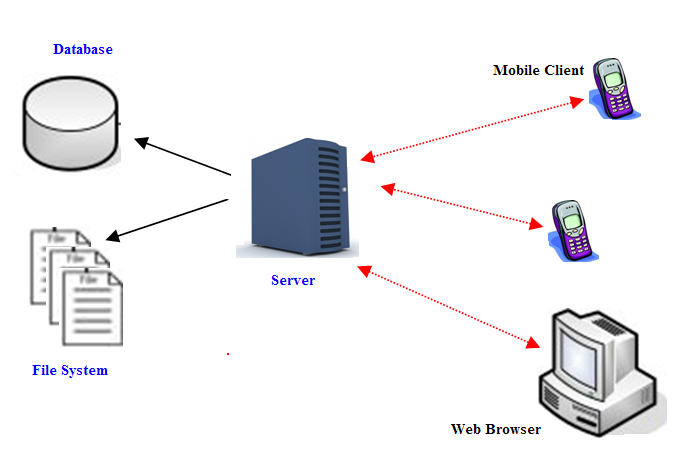
An image update simply meant deleting the disk file and invalidating the memory entry for that file. So the next call would then update the cache.
Even if our mobile app is updated to start caching images at its end, this server side cache still makes things efficient. The application server now only needs to work hard to serve the first request for an image. Subsequent requests from different clients for the same image can all be served from the disk.The advantage I see is reduced database hits to load blob data. Is this a good approach? Any ways to further optimise it ? What do you think ?
One of the issues that cropped up is caching of static or rarely changing content. (Not that this is a mobile client issue. But it came up all the same... ) The Mobile app used to show up images of contacts.
These images were served from the server application. Normally when dealing with web applications and static content, you can rely on the browser to do caching even when you haven't done anything on the server to enable it. (Guess browsers are smart or sometimes over smart. Here the server could be chipping in with suitable cache header values ;) )
For stuff like js or images, browsers do a HEAD call to check if anything has changed
If the client was a web-browser, it would cache the static page content.So for subsequent calls, we can depend on browser to do a 304 head call and if on finding that the image has not changed it picks up the content from the local cache. This is pretty well explained here.
But when writing a mobile app all this needs to be done manually. The mobile client must smartly check the headers and decide that the data has not changed and the server call is not needed.
Also with mobiles, space is a big concern. The mobile team we were working with could not decide on caching of images as they had to support a large range of mobiles and big memory availability was not a guarantee. So for now, the decision was that the client app would always hit the server to load the user's picture.
On the server end this scenario seems not too bad as long as the content is static and being served from the web application itself. A straight GET call and the resource is returned by the web server. No work for the application server.
But user's picture was a problem.
- These were calls to the web server which involved business logic to decide whose image to load.
- Also the image was in a database table. This meant a network call on the server side, to load binary content from database .
We implemented a file system based cache on the server for images.
- We built a simple map in memory to hold key-value pairs where key was the request parameter for the image and the value a disk location.
- Every time a request was received for a user's image, the server checked the map to see if the image was available on the disk.
- If yes, it loaded the image from the disk and served it. If no, then the server made a call to load the image from database and served it to the user. It also used to write the image file on the disk. The request parameter and file location were then added to the map.
- Thus subsequent requests would be resolved faster.
An image update simply meant deleting the disk file and invalidating the memory entry for that file. So the next call would then update the cache.
Even if our mobile app is updated to start caching images at its end, this server side cache still makes things efficient. The application server now only needs to work hard to serve the first request for an image. Subsequent requests from different clients for the same image can all be served from the disk.The advantage I see is reduced database hits to load blob data. Is this a good approach? Any ways to further optimise it ? What do you think ?
Then why bother to keep images in the DB? It will be easier to store then on the disk to begin with.
ReplyDeleteDirect storage on the disk has its limitations. If we were to replicate the server deployment then the different servers machines would not be able to locate the files easily. Disk space runs out after a certain point and that is another headache.
DeleteWith a database if you have everything in one place. Also if the file save is a part of one large transaction, then rollback and commit scenarios are handled automatically.
We did eventually use the disk option for another project. But the disk in this case was an S3 instance on the Amazon cloud.
Why not use a proxy cache?
ReplyDeleteProxy caching is definitely interesting but I would be more comfortable using it to cache content that is completely under my application's control - js files, css, static images in my own site etc.
DeleteCaching user pics that could change in a running application (not too frequent but nevertheless a possibility)... would require some more thought into it.
Interesting though. Thanks :)